Python Selenium实现无可视化界面过程代码解析
本篇文章小编给大家分享一下Python Selenium实现无可视化界面过程代码解析,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
无可视化界面的意义
有时候我们爬取网页数据,并不希望看其中的过程,只想看到最后的数据结果就可以了,这时候,***面就很有必要了!
代码如下
from selenium import webdriver
from time import sleep
#实现无可视化界面
from selenium.webdriver.chrome.options import Options
#实现规避检测
from selenium.webdriver import ChromeOptions
#实现无可视化界面的操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#实现规避检测
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
#如何实现让selenium规避被检测到的风险
bro = webdriver.Chrome(executable_path='./chromedriver',chrome_options=chrome_options,options=option)
#无可视化界面(无头浏览器) phantomJs
bro.get('https://www.baidu.com')
print(bro.page_source)
sleep(2)
bro.quit()
运行效果:
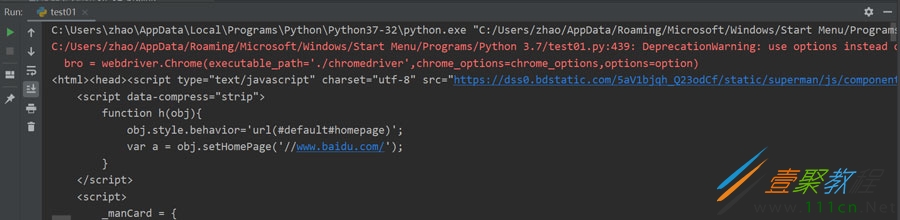
打印出网页代码,证明爬取网站信息成功。
-
上一篇: Python+Opencv身份证号码区域提取及识别实现代码
-
下一篇: Mysql命令行模式访问操作mysql数据库操作
PHP之友评论