五、DWOO中的缓存
Dwoo中已经内置了很好的缓存功能,大大提高了效率,下面讲解使用dwoo缓存的步骤:
1. 在Dwoo_Template_File的构造函数中,设定cache的名称和缓存时间。
2. 在isCached()方法中,编写相关的模版生成代码,并且当缓存存在的时候,直接返回缓存中的页面。
下面举一个搜索Twitter中信息的例子来说明如何使用缓存:
- <html>
- <head>
- <style type="text/css">...
- div.outer {...}{
- border-bottom: dashed orange 1px;
- padding: 4px;
- clear: both;
- height: 50px;
- }
- div.img {...}{
- float:left;
- padding-right: 2px;
- }
- span.attrib {...}{
- font-style: italic;
- }
- </style>
- </head>
- <body>
- <h2>{$title}</h2>
- {loop $records}
- <div class="outer">
- <div class="img"><img width=48" height="48" src="{$image}" /></div>
- <div>{$tweet} <br/> <span class="attrib">By <a href="{$uri}">{$owner}</a> on {$time}</span></div>
- </div>
- {/loop}
- </body>
- </html>
上面的模版是循环输出在Twitter中检索输出的微博内容。接下来看处理模版的PHP程序,如下:
- <?php
- include 'dwooAutoload.php';
- $dwoo = new Dwoo();
- $tpl = new Dwoo_Template_File('tmpl/tweets.tpl', 120, 'id_g75430i472j');
- //检查缓存中是否已经存在该文件,存在的话,从缓存中显示
- if ($dwoo->isCached($tpl)) {
- $dwoo->output($tpl, array());
- echo '(cached output)';
- } else {
- //缓存中不存在,直接搜索twitter
- $result = simplexml_load_file('http://search.twitter.com/search.atom?q=pasta&lang=en');
- $records = array();
- foreach ($result->entry as $entry) {
- $item['image'] = (string)$entry->link[1]['href'];
- $item['owner'] = (string)$entry->author->name;
- $item['uri'] = (string)$entry->author->uri;
- $item['tweet'] = (string)$entry->content;
- $item['time'] = date('d M Y, h:i', strtotime($entry->published));
- $records[] = $item;
- }
- $data = new Dwoo_Data();
- $data->assign('records', $records);
- $data->assign('title', $result->title);
- $dwoo->output($tpl, $data);
- }
上面的PHP代码中,首先是用isCached()方法,判断缓存中是否有该文件,如果有的话则直接读取缓存中已经合成好的页面文件显示给用户,否则的话调用twitter的Atom公开API接口去查询关键字pasta,再输出到页面。输出结果如下图:
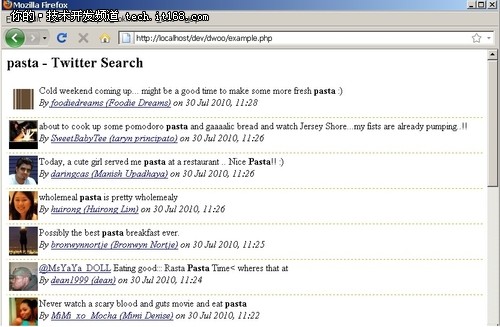
同时注意,$tpl = new Dwoo_Template_File('tmpl/tweets.tpl', 120, 'id_g75430i472j');中,第2个参数是缓存的过期时间,为120秒,第3个参数是缓存的名称,而且该名称在应用中必须是唯一的。
PHP之友评论